Maschinen-Ausfälle vorhersagen
Machine Learning und KI werden als Begriffe oft unsortiert zusammen mit Industrie 4.0 genannt. Eine zentrale Rolle spielen sie aber insbesondere für Predictive Maintenance. Die Zusammenhänge.

Machine Learning und KI werden als Begriffe oft unsortiert zusammen mit Industrie 4.0 genannt. Eine zentrale Rolle spielen sie aber insbesondere für Predictive Maintenance. Die Zusammenhänge.
Artificial Intelligence (AI: zu deutsch künstliche Intelligenz oder KI) ist der Überbegriff für Applikationen, die Funktionen menschlichen Handelns übernehmen sollen.
Machine Learning ist ein Unterbegriff der KI und bezieht sich auf Technologien, die Systeme in die Lage versetzen mittels Datensätzen und darüber laufende Algorithmen Zusammenhänge und Muster zu erkennen sowie Lösungen für Problemstellungen zu finden. Und genau darum geht es bei Predictive Maintenance.

Konkret sollen auf Basis von Datenanalysen und Machine Learning folgende Erkenntnisse geliefert werden:
Aber wie funktioniert das genau?
Die Grundvoraussetzung für Machine Learning bzw. Predictive Maintenance ist eine gute Qualität des initial zur Verfügung stehenden Datasets. Das bedeutet, dass Maschinendaten über einen bestimmten Zeitraum, im Normalfall mindestens sechs Monate, möglichst kontinuierlich und umfassend erhoben worden sein müssen. Sprich: man benötigt nicht nur Informationen über aufgetretene Fehler oder Anomalien, sondern genauso über die Phasen, in denen es keine besonderen Ereignisse gab. Das ist zwingend notwendig, denn ohne ‚normale‘ Vergleichswerte lassen sich keine Muster und Wirkungszusammenhänge um aufgetretene Fehler herum identifizieren. Weiter ist es zielführend, wenn nicht nur Daten über die Maschine selbst, sondern auch über deren Umgebung (Luftfeuchtigkeit, Temperatur etc.) erfasst worden sind.
Steht ein solches Dataset mit einer ausreichenden Menge an aufgetretenen Fehlern nun zur Verfügung, kann evaluiert werden, welcher Algorithmus für die Klassifizierung und Prognose zur Anwendung kommen soll.

Es gibt unterschiedliche Algorithmen, die in Predictive Maintenance Szenarien mit dem Ziel Fehlerkategorisierung und -vorhersage zum Einsatz kommen. Um die grundlegende Funktionsweise der Algorithmen zu erklären, ist es hilfreich, auf einen vergleichsweise einfachen zu schauen – etwa die Logistische Regression (Logistic Regression) für eine binomiale ja/nein-Klassifizierung.
Am Anfang müssen Annahmen bzgl. des Einflusses bestimmter Faktoren (Temperatur, Geschwindigkeit usw.) bzw. deren gemessene Ausprägungen auf das Auftreten von bspw. einem Fehler A gemacht werden. Das erfolgt über das Spezifizieren einer mathematischen Funktion:
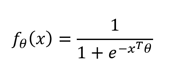
Wobei der Funktionswert als Wahrscheinlichkeit des Auftretens eines Fehlers verstanden werden kann. Der so spezifizierte Einfluss der Faktoren wird im Anschluss über das Schätzen des Parametervektors θ erfasst.

Durch das Befüllen mit Daten wird so eine binäre Prognose ermöglicht: Fehler A tritt auf: ja/nein. Das Modell liefert grundsätzlich erst einmal eine Ausfallwahrscheinlichkeit zwischen 0 und 1. Über eine Entscheidungsgrenze oder Decision Boundry, die meist auf 0,5 fixiert wird, erfolgt aber eine eindeutige Klassifizierung durch Rundung. Schätzwerte unter der Grenze werden als „nein“ interpretiert, Werte gleich oder über als „ja“.
Die so angestrengten Prognosen werden dann mit den real erfassten Fehlern im Dataset verglichen. Über Anpassungen des Models kann dann ein Finetuning gemacht werden, um die Abweichungen der Prognose von den realen Werten zu reduzieren. Alternativ gilt es zu überprüfen, ob ein anderer Algorithmus bessere Ergebnisse liefert.
Neben der Logistischen Regression gibt es komplexere Algorithmen wie etwa Support Vector Classification, Boosted Machines oder Random Forest. Zusätzlich zu binärer Klassifikation (Fehler A: ja/nein) lassen sich des Weiteren mit allen genannten Ansätzen auch multinominale Klassifizierungen abbilden. Ein Szenario wäre etwa das Schätzen, ob Fehler A, B oder C eintritt.
Um einen geeigneten Ansatz zu finden, muss also in jedem Fall initial geklärt werden, was genau klassifiziert werden soll.
Ist ein passender Algorithmus gewählt worden und durch Tests bzw. durch Abgleich mit dem initialen Dataset eine Feinjustierung der Einflussfaktoren über die jeweiligen Parameter erfolgt, kann das System in den laufenden Betrieb übernommen werden.
Im laufenden Betrieb vergrößert sich die Datenbasis kontinuierlich und kann durch den Einsatz von Machine Learning fortlaufend verbessert werden. Denn je größer die Datenbasis bzw. der Zeitraum über den Daten gesammelt werden, desto größer und umfassender die Anzahl und Vielfalt der angefallenen Fehler. Und desto präziser lassen sich Muster und Wirkungszusammenhänge schätzen.
Dabei gibt es grundsätzlich zwei Ansätze für eine kontinuierliche Optimierung:
Somit gibt es in einem Predictive Maintenance Projekt immer zwei Phasen: Das Finden und Trimmen des am besten passenden Algorithmus anhand eines initialen Datasets sowie die weitergehende Optimierung im laufenden Betrieb.

Algorithmen für ein Predictive Maintenance System können natürlich immer für den spezifischen Fall programmiert werden. Diese sind dann optimalerweise exakt auf das betreffende Szenario ausgerichtet, aber natürlich mit den entsprechenden Programmier- und Zeitaufwänden verbunden.
Anbieter wie IBM (mit Plattform Cloud Pak for Data) oder Microsoft (mit Plattform Azure) stellen über ihre Plattformen allerdings auch fertige Lösungen zur Verfügung, die diverse Funktionen und Algorithmen bereitstellen, welche man ohne großen Programmieraufwand auswählen und nutzen kann. Der SSPS Modeler von IBM bietet beispielweise visuelle Tools, mit denen man über Drag&Drop Mechanismen vergleichsweise schnell zu einem System kommen kann.
Die wichtigste Voraussetzung für ein Predictive Maintenance System ist eine solide Datenbasis. Sind Datensätze schon vorhanden, empfiehlt es sich, eine Expertenmeinung über deren Verwendbarkeit einzuholen. Anderenfalls müssen die Daten erst über einen bestimmten Zeitraum zielführend gesammelt werden.
Steht eine verwendbare Datenbasis zur Verfügung, lassen sich über Machine Learning Ansätze Prognosemodelle erstellen, die im laufenden Betrieb immer präziser werden können. Um einen schnellen Einstieg in das Thema zu finden, muss man nicht auf der grünen Wiese beginnen, sondern kann zumindest in Teilen auf vorkonfigurierte Tools zurückgreifen.



